RadixArk Raises $100M Seed to Grow SGLang Inference Engine
RadixArk, the commercial company built around the open-source SGLang inference engine, launched on May 5, 2026 with a $100M seed at a $400M valuation — co-led by Accel and Spark Capital with strategic investments from NVIDIA and AMD.
RadixArk, the commercial company spun out of the open-source SGLang inference engine, on announced a $100 million seed round at a $400 million post-money valuation — co-led by Accel and Spark Capital, with strategic backing from NVIDIA's NVentures and AMD. It is one of the largest seed rounds for any AI infrastructure company on record.
What Happened
RadixArk launched out of stealth on with a $100M seed financing led by Accel and Spark Capital. The company is built around SGLang, an Apache-2.0 inference engine first released in 2023 by co-founders Ying Sheng (CEO) and Banghua Zhu (CTO). RadixArk's stated mission is to "make frontier-level AI infrastructure open and accessible to everyone" while building a managed end-to-end platform on top of SGLang covering training, fine-tuning, RL, and inference.
According to RadixArk, SGLang is now deployed across hundreds of thousands of GPUs and serves trillions of tokens per day for customers and users that include Google, Microsoft, NVIDIA, Oracle, AMD, LinkedIn, xAI, and Thinking Machines Lab. The funding will be used to scale SGLang as an open-source project, support new model architectures, and build out commercial training and inference infrastructure for "next-generation AI applications."
Key Details
- Total raised: $100,000,000 seed at a $400M post-money valuation.
- Lead investors: Accel (lead) and Spark Capital (co-lead).
- Strategic investors: NVentures (NVIDIA), AMD, MediaTek, HOF Capital, Salience Capital, A&E Investments, Walden Catalyst Ventures, LDV Partners, WTT Investment.
- Notable angels: Igor Babuschkin (xAI co-founder), John Schulman (OpenAI / Thinking Machines Lab), Soumith Chintala (PyTorch creator, Thinking Machines Lab CTO), Lip-Bu Tan (Intel CEO), Hock Tan (Broadcom CEO), Olivier Pomel (Datadog CEO), Thomas Wolf (Hugging Face co-founder).
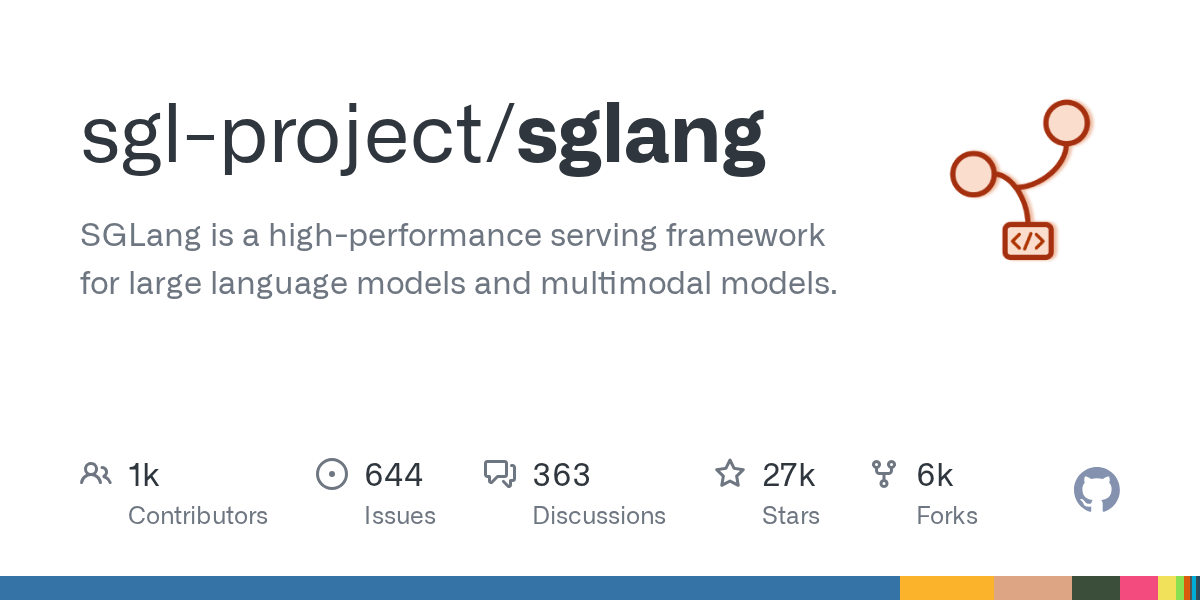
- Open-source project: SGLang remains Apache-2.0; the GitHub repo at sgl-project/sglang currently shows 27,150 stars and a last push of .
- Earlier signal: TechCrunch reported on that an SGLang spin-out was being shopped at this valuation — the May 5 announcement is the formal close.
What Developers and Users Are Saying
On Hacker News and developer forums, the dominant reaction is that this is overdue: SGLang has been quietly powering significant production AI traffic for over a year, and threads benchmarking it against vLLM consistently put SGLang 5–30% ahead on token throughput at small-model scale and roughly even at 70B+. Specific public benchmarks cite SGLang at 16,215 tok/s on H100 against vLLM's 12,553 tok/s on the same hardware — about a 29% advantage. The structured-reasoning and prefix-heavy workloads (RAG, multi-turn agents) are where developers say SGLang's RadixAttention design pulls noticeably ahead.
The skeptical view, voiced on Reddit's r/LocalLLaMA, is that vLLM has the larger contributor base and more aggressive feature cadence, and that any commercial pressure on the SGLang project — even with Apache-2.0 — bears watching. RadixArk has so far been clear that the open-source project remains independent.
What This Means for Developers
Three practical implications. First, SGLang is now backed by enough capital to keep up with the model release treadmill — expect day-zero support for new architectures (Llama, Qwen, DeepSeek, Mistral) to remain a strength. Second, RadixArk has signaled it will offer a managed platform on top of the OSS engine; teams currently rolling their own SGLang clusters can decide whether to keep self-hosting or hand operations to the vendor that writes the engine. Third, the inference market just got a third serious commercial player alongside Together AI and Fireworks — pricing pressure should intensify.
If you are choosing an inference engine today, the practical advice from the public benchmarks holds: pick SGLang for structured outputs, agentic and multi-turn workloads, and any workload that benefits from prefix caching; vLLM remains the conservative choice for vanilla high-throughput serving on stable model checkpoints.
What's Next
RadixArk says proceeds will fund SGLang's continued development, support for emerging hardware platforms (likely AMD MI300X / MI355 and MediaTek silicon, given the investor mix), and the buildout of a managed inference and training service. The company has not committed to a public release timeline for the managed platform. The SGLang project's roadmap and releases continue on GitHub.
Sources
- Business Wire — Official RadixArk launch announcement (primary source)
- TechCrunch — Sources: SGLang spins out as RadixArk at $400M valuation
- Tech Funding News — Nvidia and Accel pour $100M into RadixArk
- Rolling Out — AMD strengthens AI push with RadixArk investment
- GitHub — sgl-project/sglang (the open-source engine RadixArk stewards)
- HOF Capital — Why We Invested in RadixArk (investor perspective)
Stay up to date with Doolpa
Subscribe to Newsletter →