

 Developer Tools
Developer ToolsTempl
Type-safe HTML templating language for Go with compile-time safety
LiteLLM is the open-source AI gateway that gives you one OpenAI-format API across 100+ LLM providers, with virtual keys, spend tracking, fallbacks, and guardrails. Used in production by Stripe, Netflix, and Google.
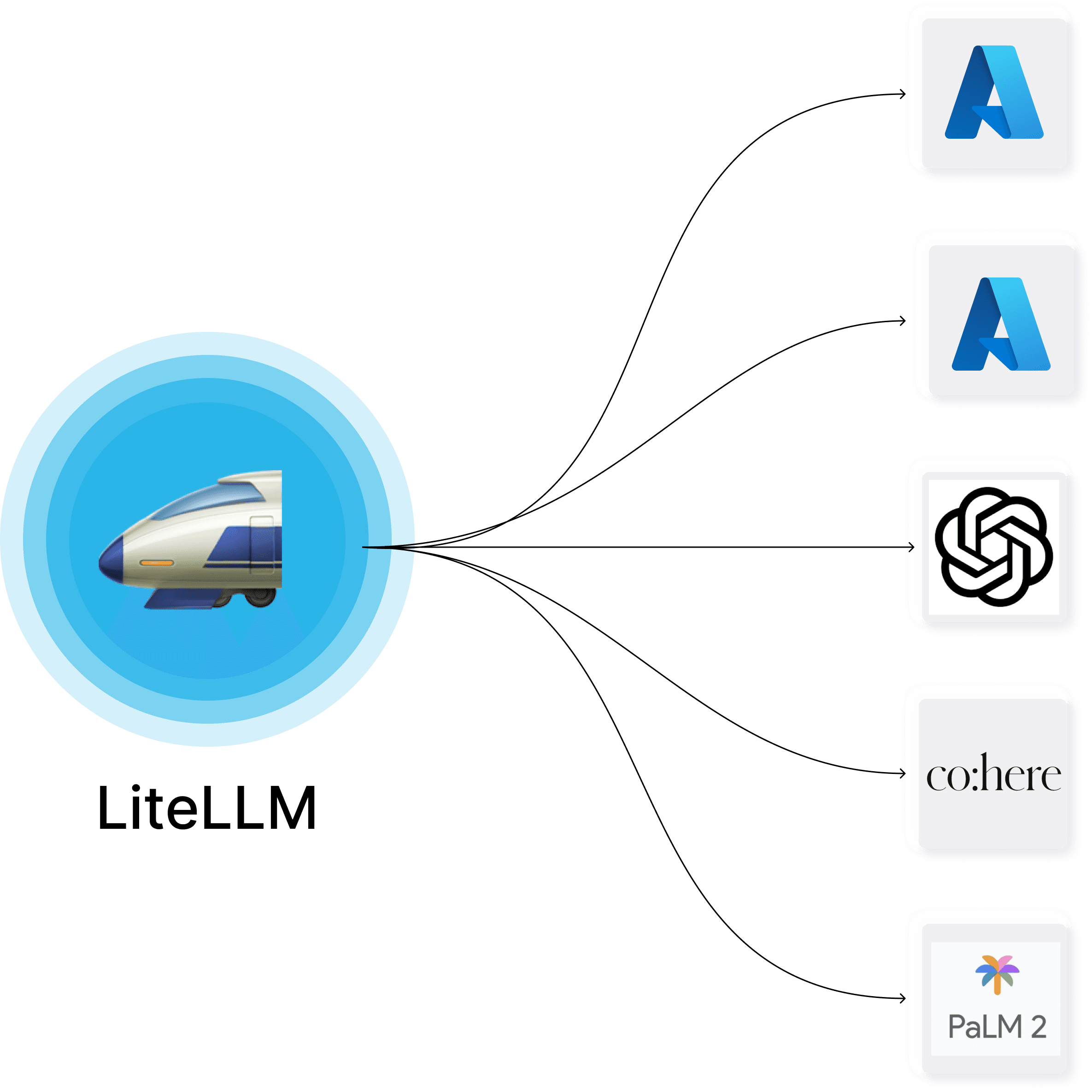
LiteLLM is an open-source AI gateway that lets you call 100+ large-language-model providers — OpenAI, Anthropic, Gemini, Bedrock, Azure, Groq, Mistral, Ollama and more — through a single OpenAI-compatible interface, and layers on virtual keys, spend tracking, guardrails, fallbacks, and observability. We rate it 84/100 — it is the default abstraction layer for teams that want to stay multi-model without rewriting their stack every time a new frontier model ships, and it scales from a one-line Python SDK import to a production proxy deployed by Stripe, Netflix and Google.
LiteLLM is built by BerriAI, a Y Combinator W23 company founded by Ishaan Jaffer and Krrish Dholakia. The first public release landed in 2023 as a thin Python shim that normalized OpenAI, Anthropic and Cohere SDKs, and the project has since grown into a full-blown AI gateway with an admin UI, virtual-key management, budgets, logging pipelines, and MCP and A2A protocol bridges. As of the latest release v1.83.7-stable on , the repository has 43.9k GitHub stars, 7.4k forks, and 1,438 contributors. OSS adopters publicly listed in the repo include Stripe, Netflix, Google ADK, OpenAI Agents SDK, Greptile and OpenHands.
The specific problem LiteLLM solves is multi-provider fragmentation. Every LLM vendor ships its own SDK, its own authentication pattern, its own request and response shape, and its own error taxonomy. Swap providers for cost, latency or reliability reasons and you are rewriting glue code. LiteLLM collapses all of that into a single OpenAI-shaped completion() call — or, if you deploy the proxy, a single base_url your team can point at from any language. That one indirection is what makes multi-model strategies tractable.
/chat/completions, /responses, /embeddings, /images, /audio, /rerank and /messages endpoints.openai, LangChain, LlamaIndex, Instructor) at http://localhost:4000 and it just works — no code changes needed.
On Hacker News, the most-upvoted thread captures the split sentiment well: developers praise how quickly LiteLLM exposes new models — several teams report being able to offer a just-released frontier model to their users on launch day without any code changes — but also flag that the proxy is “kind of a mess TBH” when you run it at scale. The most recurring complaints across Reddit's r/LocalLLaMA and r/MachineLearning are (1) gradual memory growth that requires periodic worker recycling, (2) a roughly 500 µs fixed overhead per request that some teams cite as painful for short completions, and (3) debugging requests through a proxy layer when a provider returns a weird shape. On Product Hunt the Python SDK has a near-perfect rating; the pain points cluster around the self-hosted proxy deployment, not the library itself.
LiteLLM is free and open source under the MIT license for the SDK and a permissive license for the community proxy. The commercial offering is an Enterprise tier aimed at regulated and large-scale deployments.
| Plan | Price | Key Limits |
|---|---|---|
| Open Source | $0 | 100+ provider integrations, logging, load balancing, guardrails, virtual keys, unlimited self-hosted usage |
| Enterprise | Custom (contact sales) | Adds JWT auth, SSO/SAML, SOC 2 audit logs, managed upgrades, priority support, SLA |
| Hosted Cloud | Usage-based | BerriAI-managed proxy for teams that don't want to run infra |
There are no per-seat fees on the open-source tier and no cap on request volume — the only costs you pay are to the underlying model providers you route through LiteLLM.
Best for: Backend and ML platform teams who already make more than one LLM call a second, want a single internal API for multiple providers, and need per-team budgets and audit logs. Especially strong for regulated industries (finance, healthcare) that need a self-hosted proxy with no data leaving their VPC.
Not ideal for: Solo developers building a prototype — in that case the litellm Python SDK alone is enough, the full proxy is overkill. Also skip it if you're happy being all-in on one provider; there's no value in an abstraction you never use.
Pros:
Cons:
OpenRouter offers a managed, hosted alternative with no self-hosting required — simpler, but you lose data control and self-hosted audit trails. Langfuse is complementary rather than competitive — it handles tracing and evals while LiteLLM handles routing, and the two are commonly paired. Portkey offers a closed-source SaaS gateway with a nicer UI but a less permissive licence.
For any team that has moved past the prototype stage and is making LLM calls against more than one provider, LiteLLM is the default choice — it is what Stripe, Netflix and Google build on top of, and it has more frontier-model coverage than any managed alternative. The rough edges (memory growth, 500 µs overhead, operational footprint) are real but well-documented, and the Enterprise tier exists precisely to carry those for you. Our 84/100 reflects a tool that is best-in-class at its core job but still requires platform-engineering maturity to run in production.
ServiceNow and Accenture Launch Forward Deployed Engineering Program to Scale Agentic AI in the Enterprise (May 6, 2026)
At Knowledge 2026, ServiceNow and Accenture announced a joint forward deployed engineering program that drops co-located engineer pods into customer environments to ship agentic AI workflows natively on the ServiceNow AI Platform — with access to 300+ pre-built agent skills and the AI Control Tower as the governance backbone.
May 7, 2026
ReFiBuy Raises $13.6M Seed to Help Brands Get Recommended by AI Shopping Agents (May 5, 2026)
ReFiBuy, the Raleigh-based agentic commerce platform from ChannelAdvisor founder Scot Wingo, closed an oversubscribed $13.6M seed led by NewRoad Capital Partners on May 5, 2026 — betting that the next billion-dollar e-commerce moat is being chosen by ChatGPT, Claude and Perplexity.
May 7, 2026
OpenAI Replaces ChatGPT's Default Model With GPT-5.5 Instant — 52.5% Fewer Hallucinations, 30% Shorter Answers (May 5, 2026)
OpenAI on May 5 swapped GPT-5.3 Instant for the new GPT-5.5 Instant as ChatGPT's default model, claiming 52.5% fewer hallucinated claims on high-stakes prompts and 30% more concise answers. The model also rolls into the API as chat-latest and adds personalization from Gmail and past chats for Plus and Pro web users.
May 7, 2026
Is this product worth it?
Built With
Compare with other tools
Open Comparison Tool →