
 Databases
DatabasesDuckDB
The in-process SQL OLAP database — SQLite-style embedding, columnar speed, and 1.5.2 ships DuckLake 1.0 GA.
Pinecone is a fully-managed serverless vector database that lets developers add semantic search and retrieval-augmented generation to AI apps without operating a single server. We rate it 86/100.
Pinecone is a fully-managed, serverless vector database that lets developers store, search and retrieve high-dimensional embeddings for retrieval-augmented generation (RAG), semantic search and recommendation systems — with no servers to provision and no clusters to tune. We rate it 86/100 — the easiest way to ship a vector search backend in production, with a real cost ceiling that teams operating at very large scale should map out before committing.
Pinecone is the vector database company founded by Edo Liberty in . Liberty was previously a Director of Research at AWS and Head of Amazon AI Labs, and watched in-house teams build custom vector search systems while smaller teams had nothing comparable to use. Pinecone, launched publicly in , was the first packaged answer — and effectively created the "vector database" product category that now includes Weaviate, Qdrant, Chroma, Milvus and pgvector.
The company raised a $10M seed in 2021, a $28M Series A and a $100M Series B at a $750M valuation led by Andreessen Horowitz in , with participation from ICONIQ Growth, Menlo Ventures and Wing. Today Pinecone reports more than 4,000 paying customers including Notion, Shopify, Gong and HubSpot, and serves billions of queries per day.
The pitch is simple: every modern AI feature — chat-with-your-docs, smart recommendations, semantic product search, agent memory — needs to retrieve the most semantically similar items from a large corpus in milliseconds. Pinecone takes care of the indexing, sharding, replication and scaling so you can ship that feature in an afternoon instead of a quarter.
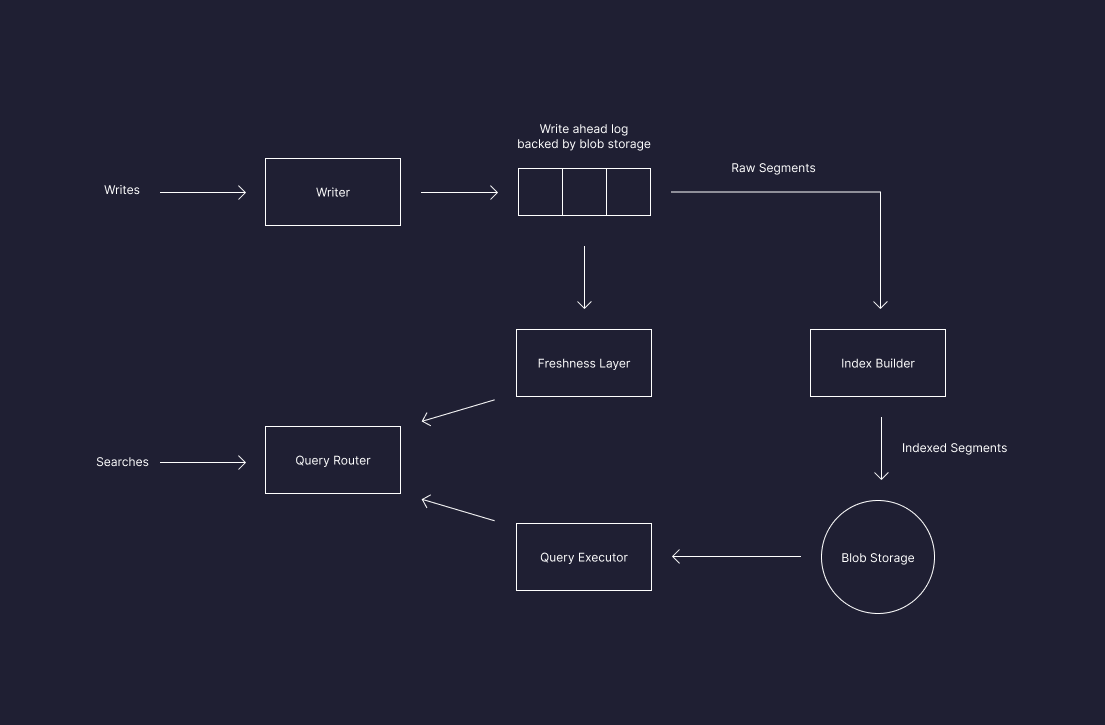
tenant_id, language, doc_type) without slowing down ANN search.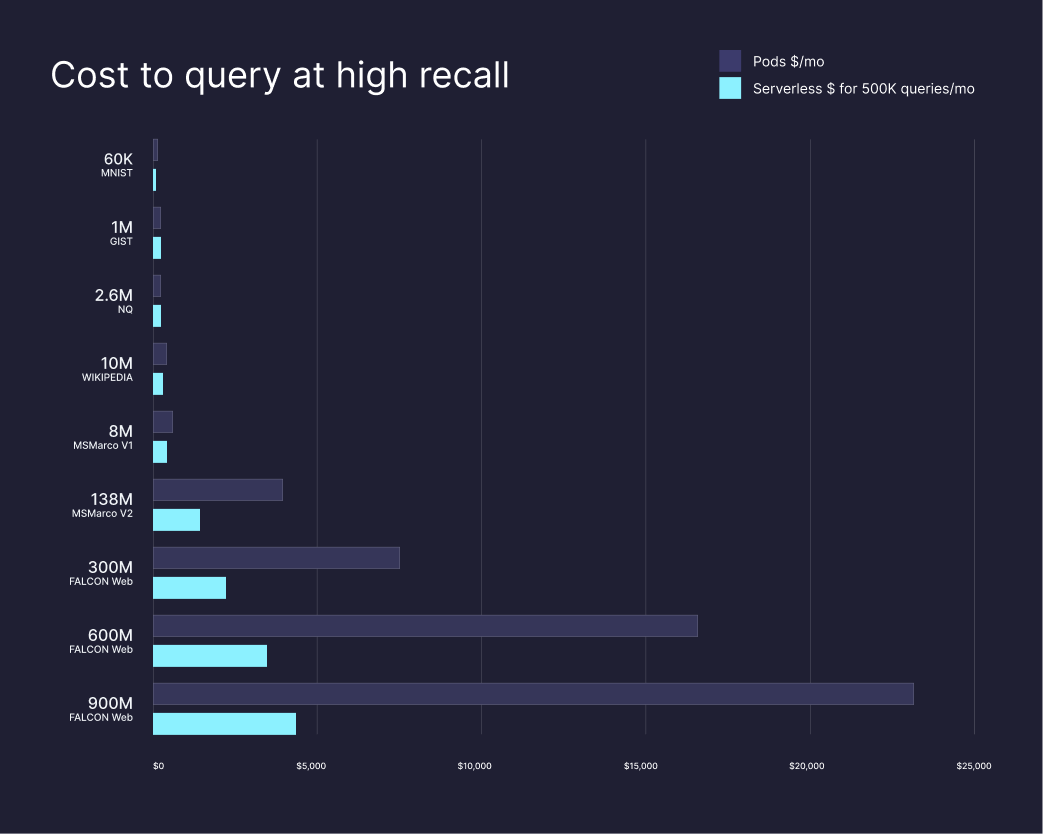
Sentiment is genuinely split. On G2 and Hacker News, the most-quoted praise is that Pinecone "just works" — teams ship a working RAG backend in an afternoon, the latency is consistently fast even under load, and the documentation is among the cleanest in the AI infra space. Founders on Product Hunt and r/MachineLearning specifically call out the serverless launch as the moment Pinecone became affordable for side projects.
The recurring complaint is cost at scale. A widely-shared write-up on r/LangChain documented a RAG chatbot whose Pinecone bill went from $50 in month one to $380 in month two and roughly $2,800 in month three as traffic grew, mainly because each query with metadata filtering can consume 5–10 read units rather than one. Cost-conscious engineers on Hacker News repeatedly point out that Qdrant self-hosted on a $30/month VPS handles 10M+ vectors comfortably, and that pgvector on existing Postgres is "good enough" for many production workloads.
Pinecone uses a usage-based, serverless-first pricing model. The free Starter tier covers small projects and prototypes; everything above that is paid by storage, read units, write units and (on Standard and above) a fixed minimum monthly fee.
| Plan | Price | Key Limits |
|---|---|---|
| Starter | $0/month | Up to 2 GB storage, 2M write units and 1M read units per month, 5 indexes, community support. |
| Standard | From $50/month minimum + usage | Unlimited indexes and namespaces, usage-based pricing, email support, multi-region. |
| Enterprise | From $500/month minimum + usage | Higher minimums, SOC 2 + HIPAA, BYOC, SSO, dedicated support and 99.95% SLA. |
| Pinecone Inference / Assistant | Pay per token | Hosted embeddings, rerankers and managed RAG assistant priced per million tokens. |
Storage is roughly $0.33/GB/month, write units are about $4 per 1M and read units about $16 per 1M on Standard. A typical 10M-vector RAG workload sits around $70–$100/month all-in — competitive against Weaviate Cloud (≈$135) and roughly the same as Qdrant Cloud (≈$65), but more than self-hosted pgvector or Qdrant on a small VPS.
Best for: Application teams shipping AI features — RAG chatbots, semantic search, recommendation systems, agent memory — that want a managed, low-operations vector database with predictable latency and don't want to run their own infra. Particularly strong for SaaS products that need namespace-level multi-tenancy out of the box, and for enterprises that need SOC 2 / HIPAA and BYOC.
Not ideal for: Cost-sensitive solo developers and bootstrapped startups whose workloads will grow into hundreds of millions of vectors — self-hosted Qdrant or pgvector on existing Postgres can be 5–10× cheaper at that scale. Also not the best fit for teams that need full schema flexibility or complex graph relations alongside their vectors.
Pros:
Cons:
The vector database market is crowded in 2026. Qdrant is the most popular open-source alternative — Rust-based, very fast and self-hostable for a fraction of the cost. Weaviate bundles vector search with a richer schema and built-in modules but is more expensive in their managed cloud. Chroma is the easiest way to start locally, ideal for prototypes. pgvector turns any Postgres database into a vector store and is increasingly "good enough" for many production workloads under 50M vectors. Milvus remains the open-source choice for the very largest deployments. For a managed analytical alternative we've also reviewed ClickHouse, which now ships its own vector index for hybrid analytics + search workloads.
If your team values shipping speed and operational simplicity over absolute cost, Pinecone is still the safest choice in 2026. The serverless model has fixed the worst of the old pricing complaints, the latency is consistently excellent, and the SDKs are best-in-class. We rate it 86/100 — an outstanding managed product whose only real flaw is that bills can balloon at the largest scales. If you're a startup shipping your first AI feature, start with Pinecone. If you're running an established workload with predictable, very large vector volumes and an SRE team, price out self-hosted Qdrant or pgvector before you commit.
ServiceNow and Accenture Launch Forward Deployed Engineering Program to Scale Agentic AI in the Enterprise (May 6, 2026)
At Knowledge 2026, ServiceNow and Accenture announced a joint forward deployed engineering program that drops co-located engineer pods into customer environments to ship agentic AI workflows natively on the ServiceNow AI Platform — with access to 300+ pre-built agent skills and the AI Control Tower as the governance backbone.
May 7, 2026
ReFiBuy Raises $13.6M Seed to Help Brands Get Recommended by AI Shopping Agents (May 5, 2026)
ReFiBuy, the Raleigh-based agentic commerce platform from ChannelAdvisor founder Scot Wingo, closed an oversubscribed $13.6M seed led by NewRoad Capital Partners on May 5, 2026 — betting that the next billion-dollar e-commerce moat is being chosen by ChatGPT, Claude and Perplexity.
May 7, 2026
OpenAI Replaces ChatGPT's Default Model With GPT-5.5 Instant — 52.5% Fewer Hallucinations, 30% Shorter Answers (May 5, 2026)
OpenAI on May 5 swapped GPT-5.3 Instant for the new GPT-5.5 Instant as ChatGPT's default model, claiming 52.5% fewer hallucinated claims on high-stakes prompts and 30% more concise answers. The model also rolls into the API as chat-latest and adds personalization from Gmail and past chats for Plus and Pro web users.
May 7, 2026
Is this product worth it?
Built With
Compare with other tools
Open Comparison Tool →

