

 Databases
DatabasesDragonfly
A Redis-compatible in-memory data store engineered for 25× throughput on a single multi-core box.
DuckDB is a free, open-source, in-process analytical database that runs anywhere SQLite would — and now, with DuckLake 1.0, it doubles as a production lakehouse engine. We rate it 92/100.
DuckDB is the in-process analytical database that does for OLAP what SQLite did for OLTP — embed it in your Python script, your CLI, your Rust binary or your browser tab and query Parquet, CSV, JSON and Iceberg at columnar speed without spinning up a server. We rate it 92/100 — the right pick for any analyst, data engineer or backend team that wants warehouse-grade SQL on a laptop, and the wrong pick only if you need a multi-tenant OLTP database with row-level concurrency.
DuckDB started in 2018 as an academic project at CWI Amsterdam, led by Hannes Mühleisen and Mark Raasveldt, who wanted a SQLite-style embedded database that was actually fast on analytical workloads. They spun the project out into the non-profit DuckDB Foundation in 2022 and the for-profit DuckDB Labs shortly after. The 1.0 release shipped in June 2024; the most recent stable, v1.5.2, was released on , alongside the production GA of the DuckLake 1.0 lakehouse format.
The core pitch is: every row of analytical SQL you would normally send to Snowflake, BigQuery or ClickHouse can run inside your application process, against files on local disk or S3, with zero network hop and zero per-query cost. The same engine can vector-scan a 50 GB Parquet file from your machine, run a federated join against a Postgres replica, and now act as a metadata-managed lakehouse compute layer through DuckLake. Pandas users in particular have been migrating wholesale: DuckDB queries DataFrames in place via duckdb.sql("SELECT * FROM df") with no copy and routinely beats native Pandas by 10× or more on multi-GB joins.
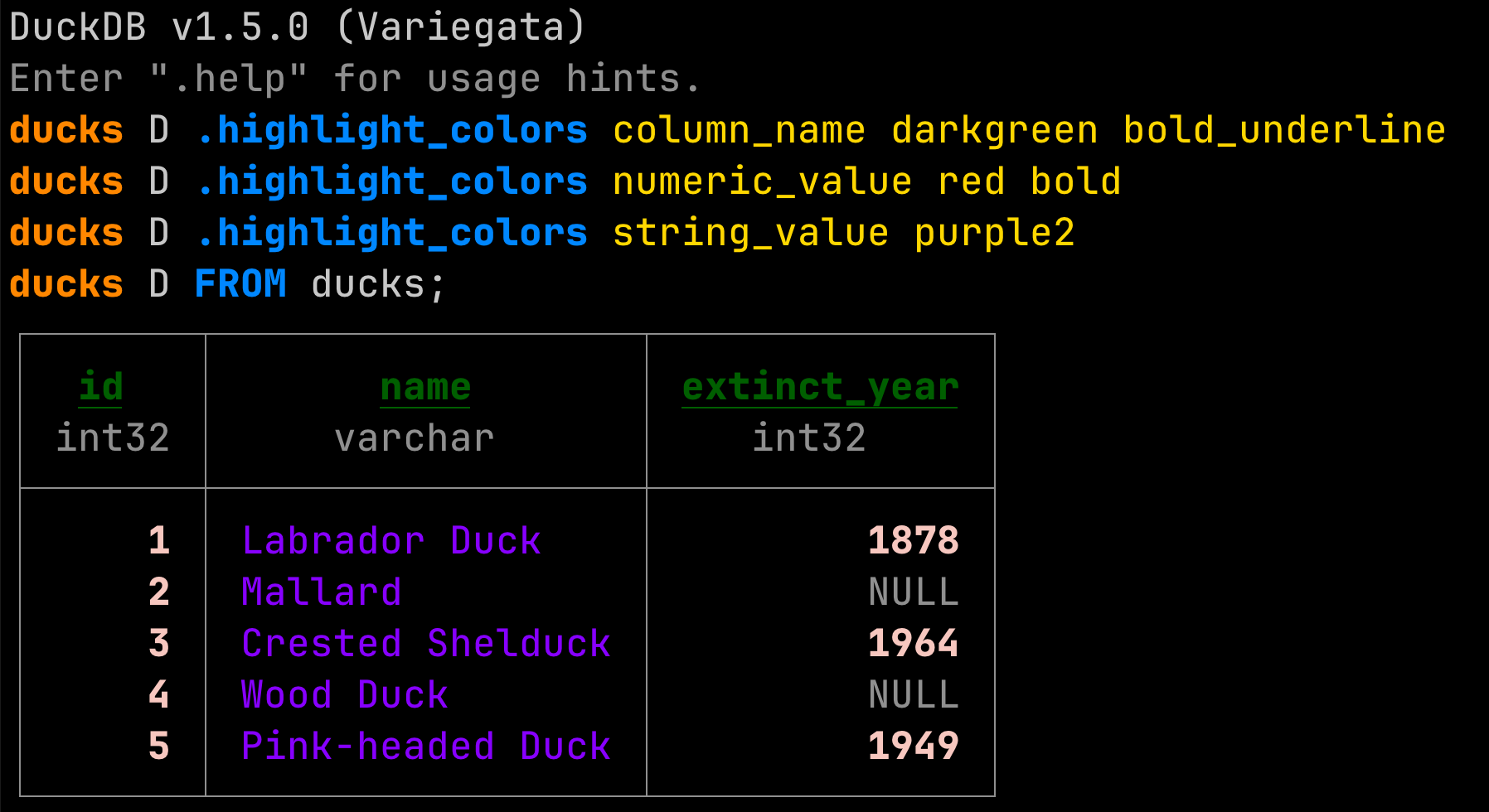
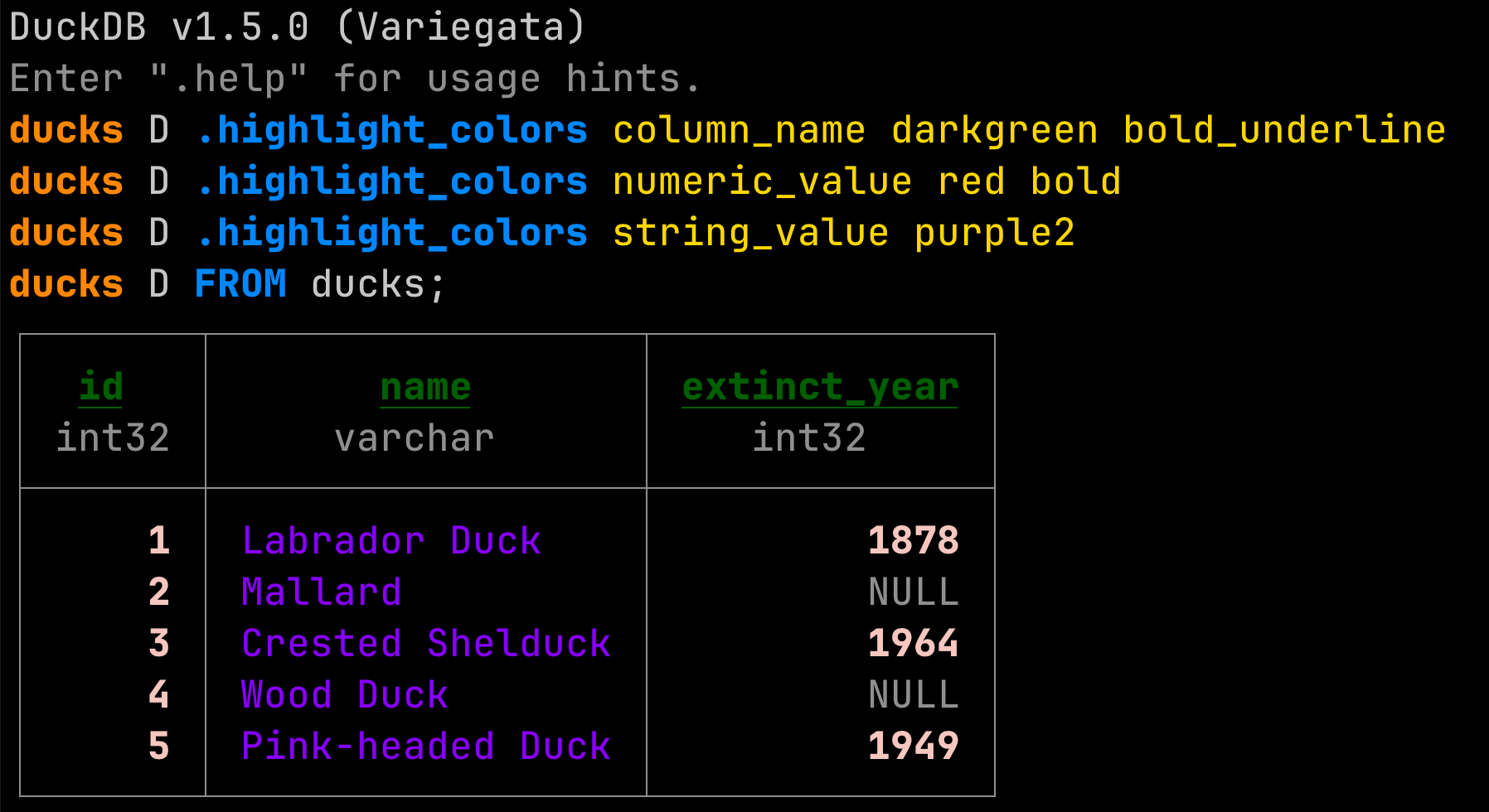
SELECT * FROM 'data/*.parquet' over local disk, S3, GCS, Azure Blob and now OneLake — no ETL, no load step, no separate reader process..files command, and a PEG-based parser that produces dramatically better error messages.
Sentiment is overwhelmingly positive across r/dataengineering, r/Python, r/SQL and Hacker News — to a degree that is rare for any infrastructure tool. The most upvoted Hacker News thread on DuckDB in early 2026 ("Why DuckDB is my first choice for data processing") describes it as "mind-blowingly awesome… like SQLite, lightweight, embeddable, but for analytics" and the comments are full of practitioners reporting they've replaced Pandas pipelines, ad-hoc Spark jobs and even small Snowflake warehouses. MotherDuck reports the project's headline count grew 50.7% year-over-year in 2025, with half its all-time front-page Hacker News stories appearing in the last 12 months.
The recurring complaints are honest and consistent. First, single-writer concurrency: only one process can write to a DuckDB file at a time, which surprises engineers expecting Postgres-style behavior — DuckLake and the upcoming distributed mode are explicit responses to this. Second, memory pressure on truly massive joins: DuckDB now spills to disk, but pre-1.5 OOM kills are still cited on Reddit, especially in containers with low RAM limits. Third, the ecosystem is moving fast and breaking things — minor releases occasionally tweak SQL semantics or extension APIs in ways that bite production users. None of these are dealbreakers; they are the predictable cost of being on the bleeding edge of analytical data.
DuckDB itself is free and open source under the MIT license — no paid tiers, no telemetry, no per-seat fees, no usage limits. You can ship it inside a commercial product without licensing it, fork it, run it offline, or download the binary and never talk to duckdb.org again. The DuckDB Foundation is funded by donations and contracts; the for-profit DuckDB Labs sells consulting and custom engineering, not seats.
| Product | Price | Notes |
|---|---|---|
| DuckDB (engine) | $0 | MIT license, all features, all platforms, no limits |
| MotherDuck Free | $0/month | Cloud DuckDB — 10 GB storage, included compute |
| MotherDuck Pulse | per compute-second | Pay-as-you-go for cloud DuckDB workloads |
| MotherDuck Business | $250/month | Org features, fixed-capacity compute, SSO |
You only pay anything if you choose MotherDuck — the managed cloud service from the DuckDB founders — to host a multi-user DuckDB warehouse with auth, sharing and serverless compute. Storage is roughly $0.08 per GB-month on paid plans. The DuckDB engine itself remains free in every other deployment.
Best for: Data engineers and analysts who currently glue together Pandas, Parquet and ad-hoc Spark; backend teams that need embedded analytical SQL in a desktop or server app; anyone running interactive notebooks against multi-GB files on a laptop; teams who want to replace a small Snowflake or BigQuery warehouse with something cheaper. The DuckLake 1.0 GA in 1.5.2 also makes DuckDB credible as the compute engine for a self-managed lakehouse on S3.
Not ideal for: High-concurrency OLTP — use Supabase or Postgres directly. Multi-tenant SaaS where many tenants write the same database simultaneously. Workloads that genuinely need petabyte-scale distributed query processing, where ClickHouse or BigQuery still win.
Pros:
Cons:
ClickHouse — a server-based columnar OLAP engine; faster at petabyte scale, much heavier to operate. SQLite — still the right choice for OLTP and tiny embedded apps; DuckDB is what you reach for once your queries become analytical. Polars — a Rust DataFrame library with overlapping benchmarks; great if you prefer DataFrame APIs and don't need SQL or persistent storage. Apache DataFusion — a similar Rust-based query engine, often used as a building block rather than a finished product.
If you write any analytical SQL at all, DuckDB has earned a permanent slot on your machine. It is the rare piece of infrastructure that is simultaneously free, fast, well-engineered, well-documented and aimed squarely at the work you actually do. The 1.5.2 release with DuckLake 1.0 GA pushes it from "great for laptops and small services" to "credible production analytics platform." Skip it only if your workload is truly transactional or truly distributed at petabyte scale; for everything in between, our 92/100 reflects how hard it is to find a meaningful weakness.
ServiceNow and Accenture Launch Forward Deployed Engineering Program to Scale Agentic AI in the Enterprise (May 6, 2026)
At Knowledge 2026, ServiceNow and Accenture announced a joint forward deployed engineering program that drops co-located engineer pods into customer environments to ship agentic AI workflows natively on the ServiceNow AI Platform — with access to 300+ pre-built agent skills and the AI Control Tower as the governance backbone.
May 7, 2026
ReFiBuy Raises $13.6M Seed to Help Brands Get Recommended by AI Shopping Agents (May 5, 2026)
ReFiBuy, the Raleigh-based agentic commerce platform from ChannelAdvisor founder Scot Wingo, closed an oversubscribed $13.6M seed led by NewRoad Capital Partners on May 5, 2026 — betting that the next billion-dollar e-commerce moat is being chosen by ChatGPT, Claude and Perplexity.
May 7, 2026
OpenAI Replaces ChatGPT's Default Model With GPT-5.5 Instant — 52.5% Fewer Hallucinations, 30% Shorter Answers (May 5, 2026)
OpenAI on May 5 swapped GPT-5.3 Instant for the new GPT-5.5 Instant as ChatGPT's default model, claiming 52.5% fewer hallucinated claims on high-stakes prompts and 30% more concise answers. The model also rolls into the API as chat-latest and adds personalization from Gmail and past chats for Plus and Pro web users.
May 7, 2026
Is this product worth it?
Built With
Compare with other tools
Open Comparison Tool →

