DeepSeek V4 Preview Released: 1.6T-Param Pro Model, 1M Context, and Frontier Performance at $1.74/M Tokens (April 2026)
Hangzhou-based DeepSeek on April 24, 2026 open-sourced V4-Pro (1.6T parameters / 49B active) and V4-Flash (284B / 13B), both with a 1M-token context window and MIT license. V4-Pro undercuts Gemini 3.1 Pro and GPT-5.4 by 2-7x while landing within striking distance on benchmarks.
Chinese AI lab DeepSeek on open-sourced the preview of its long-anticipated V4 series — two Mixture-of-Experts models that ship with a native 1-million-token context window, MIT-licensed open weights on Hugging Face, and API pricing that undercuts every Western frontier lab by a factor of 2 to 7. The release marks the first major DeepSeek model since V3.2 in December 2025 and arrives one year after the Hangzhou-based startup's R1 launch triggered the so-called "Sputnik moment" that wiped roughly $1 trillion off Western AI stocks.
What Happened
DeepSeek published the V4 Preview on its official API docs at roughly 06:00 UTC on April 24, with the open-weight checkpoints landing simultaneously on the deepseek-ai Hugging Face collection. The series ships in two variants:
- DeepSeek-V4-Pro — 1.6 trillion total parameters with 49 billion active per token. At 865 GB on Hugging Face, it is now the largest open-weight model in the world, surpassing Kimi K2.6 (1.1T) and GLM-5.1 (754B), and is more than twice the size of V3.2.
- DeepSeek-V4-Flash — 284B total parameters with 13B active. The 160 GB Flash model is the cheaper, faster sibling, intended to anchor the bottom of DeepSeek's API price card.
Both models are released under the standard MIT license, allowing free commercial use, and both are exposed via the existing DeepSeek API by simply switching the model parameter to deepseek-v4-pro or deepseek-v4-flash. The legacy deepseek-chat and deepseek-reasoner endpoints will be retired on , and are currently routed to V4-Flash. The API also speaks both OpenAI ChatCompletions and Anthropic-compatible payload formats, and exposes a dual Thinking / Non-Thinking mode toggle on every request.

Key Details
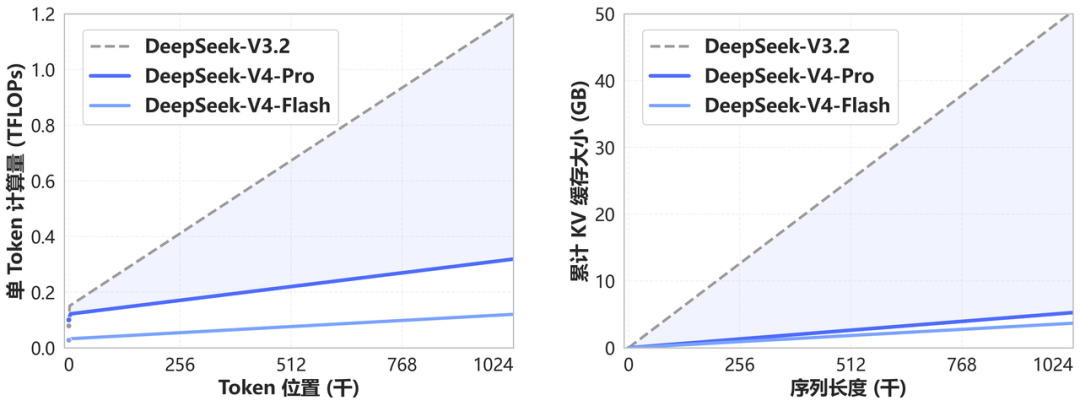
- Novel attention architecture — DeepSeek calls it "token-wise compression + DSA (DeepSeek Sparse Attention)". In the 1M-token regime, V4-Pro uses only 27% of the single-token FLOPs and 10% of the KV-cache size of V3.2; V4-Flash drops those numbers to 10% and 7%, respectively.
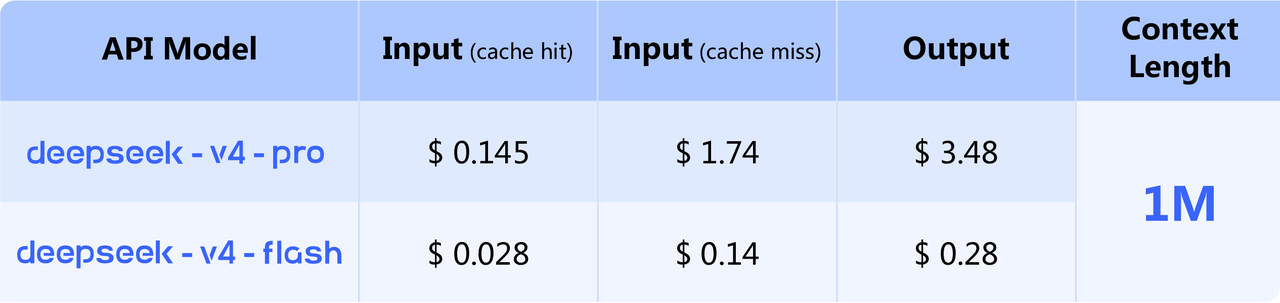
- API pricing — $0.14 / million input tokens and $0.28 / million output tokens for Flash, and $1.74 / $3.48 for Pro. By Simon Willison's published comparison, that makes Flash the cheapest small model on the public market — beating GPT-5.4 Nano ($0.20 / $1.25) — and Pro the cheapest of the larger frontier-class models, undercutting Gemini 3.1 Pro ($2 / $12) and GPT-5.4 ($2.50 / $15) by 2-7x on output tokens alone.
- Self-reported benchmarks — DeepSeek claims V4-Pro is the open-source state of the art on agentic-coding benchmarks and trails only Gemini 3.1 Pro on world-knowledge evaluations among open models. The technical report concedes that with extended reasoning tokens, V4-Pro-Max sits roughly 3-6 months behind GPT-5.4 and Gemini 3.1 Pro on the absolute frontier.
- Agent integration on day one — V4 is pre-integrated with Claude Code, OpenClaw, and OpenCode, and DeepSeek says the model already drives its own internal agentic-coding workflows.
What Developers and Researchers Are Saying
On Hacker News, the top comment on the launch thread (item 47884971) called V4-Pro "frontier level (better than Opus 4.6) at a fraction of the cost," and the thread is dominated by debate over whether the self-reported benchmarks will hold up against independent evaluations like Artificial Analysis or LiveCodeBench. Independent ML practitioner Simon Willison ran both models through his standard "pelican on a bicycle" SVG test via OpenRouter and concluded the pricing is the real story: "DeepSeek-V4-Flash is the cheapest of the small models, beating even OpenAI's GPT-5.4 Nano. DeepSeek-V4-Pro is the cheapest of the larger frontier models."
Reaction in the broader press was mixed but attentive. CNBC framed V4 as proof that the US-China AI race is "not over"; MIT Technology Review argued the bigger story is the efficiency math, not the leaderboard score; and TechCrunch noted DeepSeek's continued silence on training compute and data sources. ML researcher reactions on r/LocalLLaMA were more cautious — multiple users pointed out that a 1.6T-parameter model is unrunnable on consumer hardware even with aggressive quantization, and some questioned whether the "open" V4-Pro is practically open in any meaningful sense without a hosting partner.
What This Means for Developers
The immediate impact is on cost. Any team currently routing high-volume traffic through GPT-5.4, Claude Sonnet 4.6, or Gemini 3.1 Pro can now plausibly A/B test against V4-Pro and capture a 60-90% reduction in per-token cost, particularly on output-heavy workloads such as code generation and long-document summarization. The 1M-token context window — now the default rather than an opt-in — also makes V4 immediately attractive for codebase-aware agents and long-document RAG pipelines. Migration is a one-line change for OpenAI-compatible clients: keep the base URL, swap the model name, and remember to disable any application-level chunking that assumes a smaller window. Teams using LiteLLM, OpenRouter, or Cline can route to V4 today without touching client code.
The catch: legacy deepseek-chat and deepseek-reasoner endpoints disappear on July 24, 2026 (15:59 UTC), so any production integration on those model strings has roughly 90 days to migrate. Teams with strict data-residency or geopolitical constraints around Chinese-hosted inference should plan around either self-hosting the open weights, routing via OpenRouter or a US-based inference provider, or staying on a Western frontier model.
What's Next
The V4 release is officially marked a Preview; DeepSeek's tech report flags V4-Pro-Max — a higher-reasoning-token variant — as the model intended to close the remaining gap to GPT-5.4 and Gemini 3.1 Pro. Quantized Flash builds from the Unsloth team are expected to land within days, which should make local single-GPU inference viable on consumer hardware. The full V4 technical report is published as a PDF inside the DeepSeek-V4-Pro Hugging Face repo, and a stable (post-Preview) release is expected ahead of the July 24 deprecation date for legacy endpoints.
Sources
- DeepSeek API Docs — V4 Preview Release — primary source: official announcement and pricing
- Hugging Face — DeepSeek-V4 collection — open weights and technical report PDF
- Simon Willison — DeepSeek V4 — almost on the frontier, a fraction of the price — independent technical analysis with full pricing table
- TechCrunch — DeepSeek previews new AI model that closes the gap with frontier models
- CNBC — China's DeepSeek releases preview of long-awaited V4 model
- MIT Technology Review — Three reasons why DeepSeek's new model matters
- Hacker News discussion thread (item 47884971) — developer reactions and benchmark debate
Stay up to date with Doolpa
Subscribe to Newsletter →