
 Hosting & Infrastructure
Hosting & InfrastructurePi-hole
Network-wide ad blocker and DNS sinkhole — kills ads on every device on your network without any client software
Modal is a serverless Python and GPU cloud that lets AI teams ship inference, fine-tuning and batch jobs without touching Dockerfiles or Kubernetes. We rate it 86/100 for its unmatched developer experience, though regional and non-preemption multipliers mean real production bills run well above the headline per-second prices.
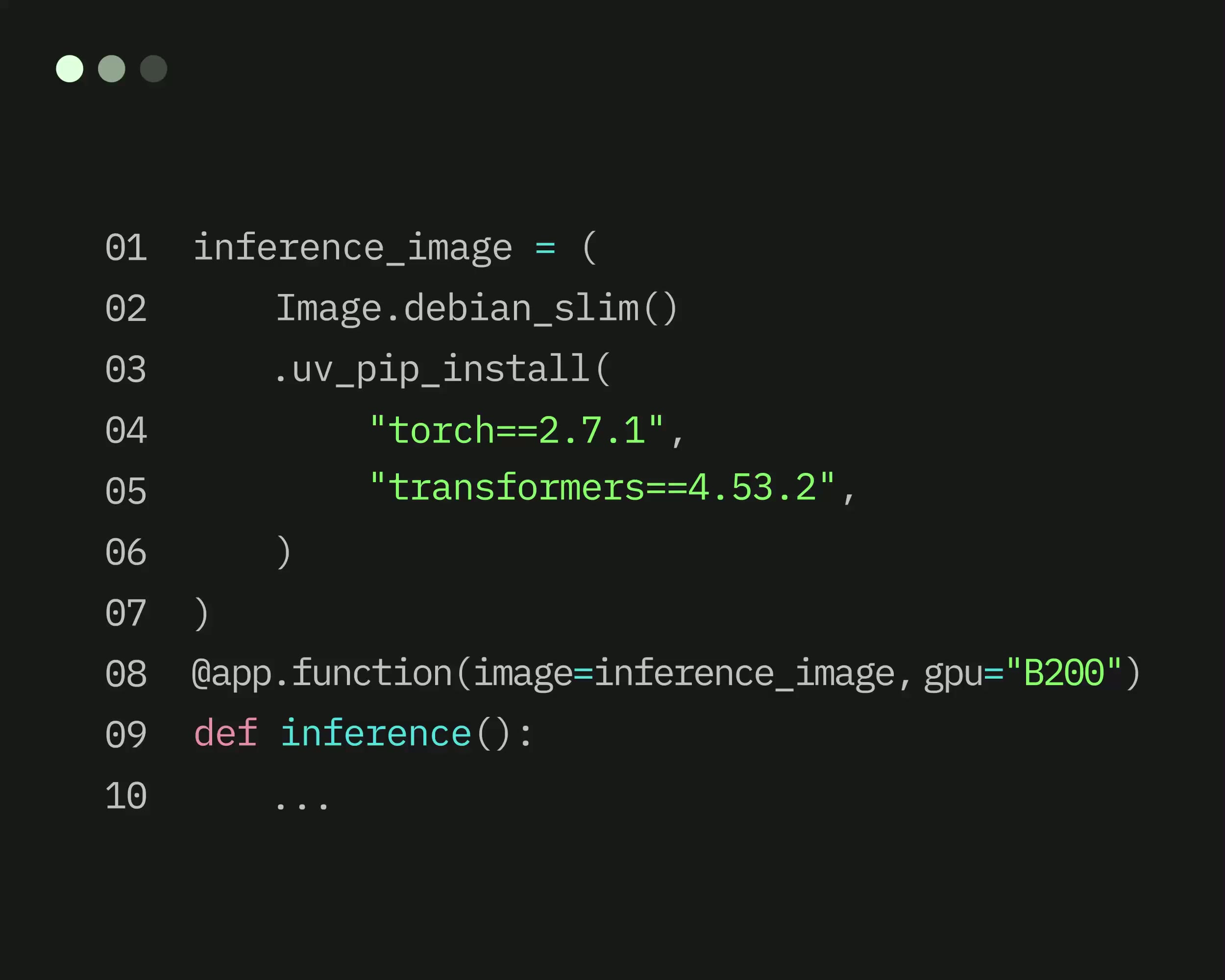
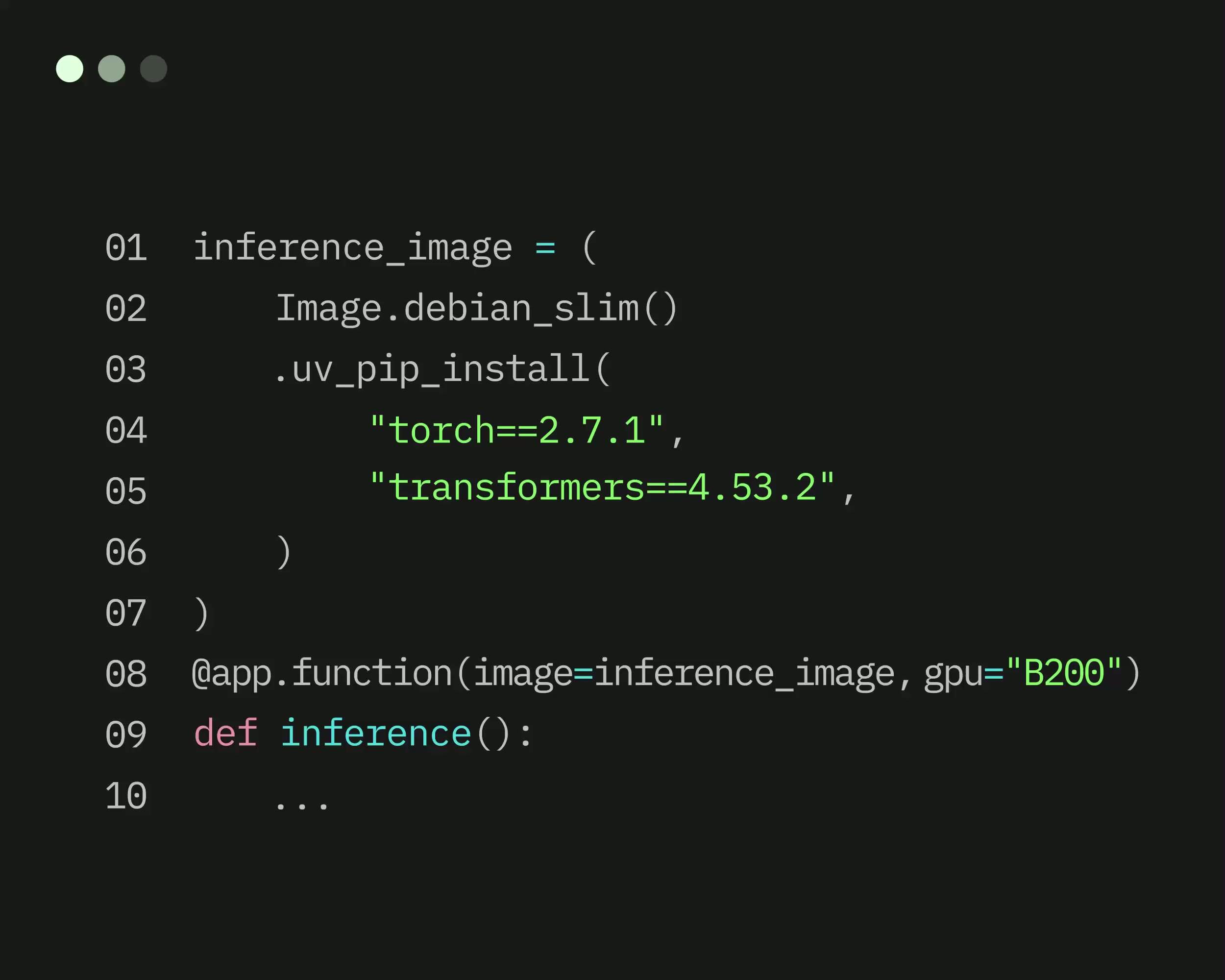
Modal is a serverless Python and GPU cloud built for AI teams: you decorate a function with @app.function(), run modal deploy, and your code is live behind an HTTPS endpoint with sub-second cold starts and autoscaling from zero to thousands of containers. We rate it 86/100 — the best developer experience in the serverless GPU category for Python-native teams, let down only by a pricing model whose regional and non-preemption multipliers make production bills in the US comfortably 3–4x the headline per-second rates.
Modal was founded in by Erik Bernhardsson (former Spotify and Better.com engineering leader, author of the Annoy nearest-neighbor library) and joined that August by co-founder and CTO Akshat Bubna. The company's pitch is "the cloud for AI, without the DevOps" — bring your Python, keep your laptop workflow, and let Modal handle containers, schedulers, GPU provisioning, storage and networking.
Under the hood Modal ships a custom container runtime, a lazy-loading filesystem and an intelligent scheduler that together deliver cold starts measured in hundreds of milliseconds even for multi-gigabyte model weights. The public SDK at github.com/modal-labs/modal-client is Apache-2.0 licensed and the modal-examples repo has crossed 1,100+ stars. On the business side, Modal raised a $7M Seed in 2022, a $16M Series A led by Redpoint Ventures, and an $87M Series B in July 2025. Named production customers include Ramp, Scale AI, Substack, Suno, Cohere and Quora/Poe.
app.py, Modal builds and caches layers for you.@app.schedule, with streaming support and automatic websocket termination at Modal's edge.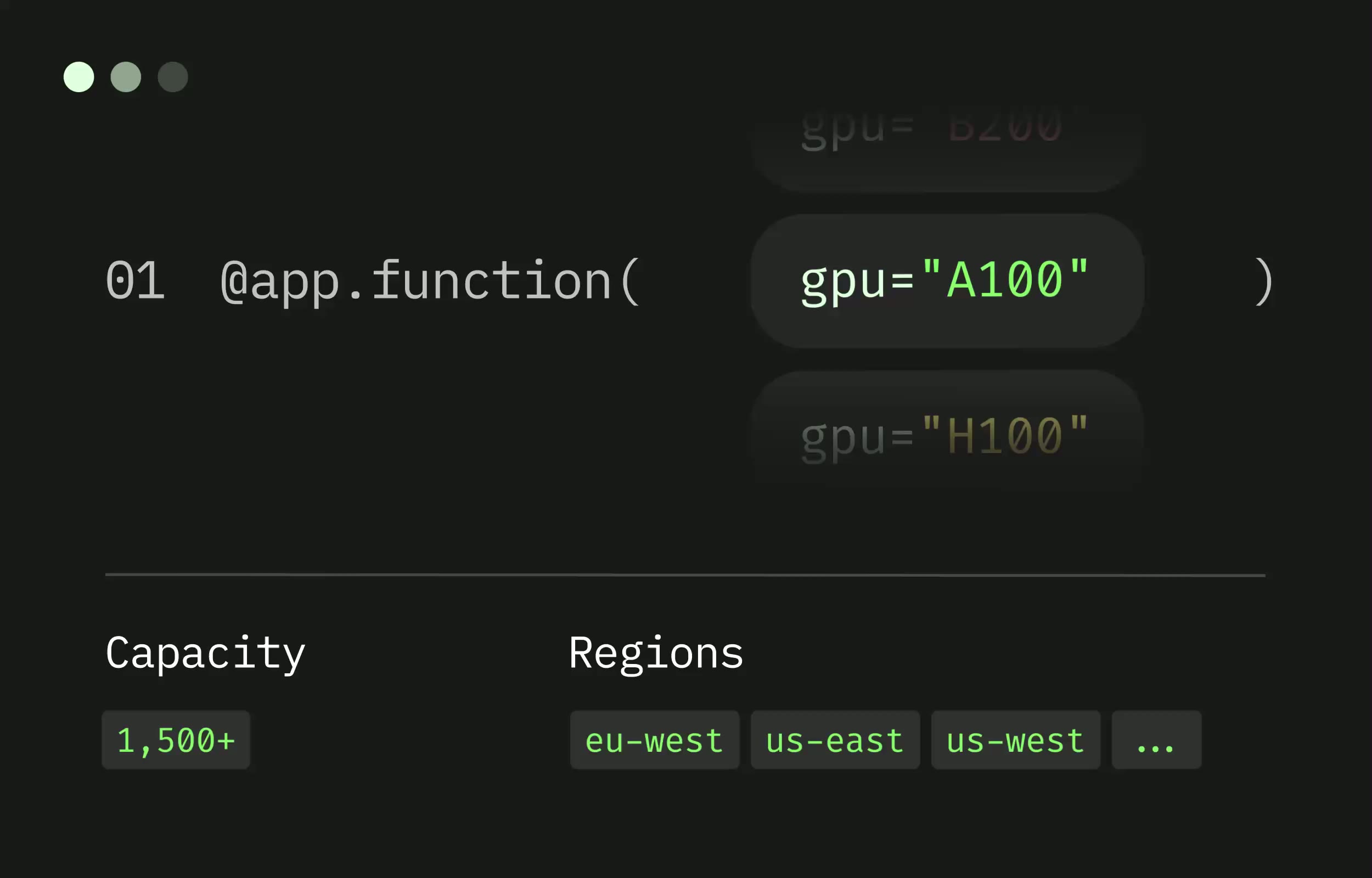
Sentiment on Hacker News and r/MachineLearning skews strongly positive, with the same phrase recurring: "I hate DevOps and just want to ship — Modal, it's not even close." Substack, Ramp and early Suno engineers have written publicly about picking Modal over AWS SageMaker and Google Vertex specifically because the iteration loop is tight enough to treat infra changes like normal code commits.
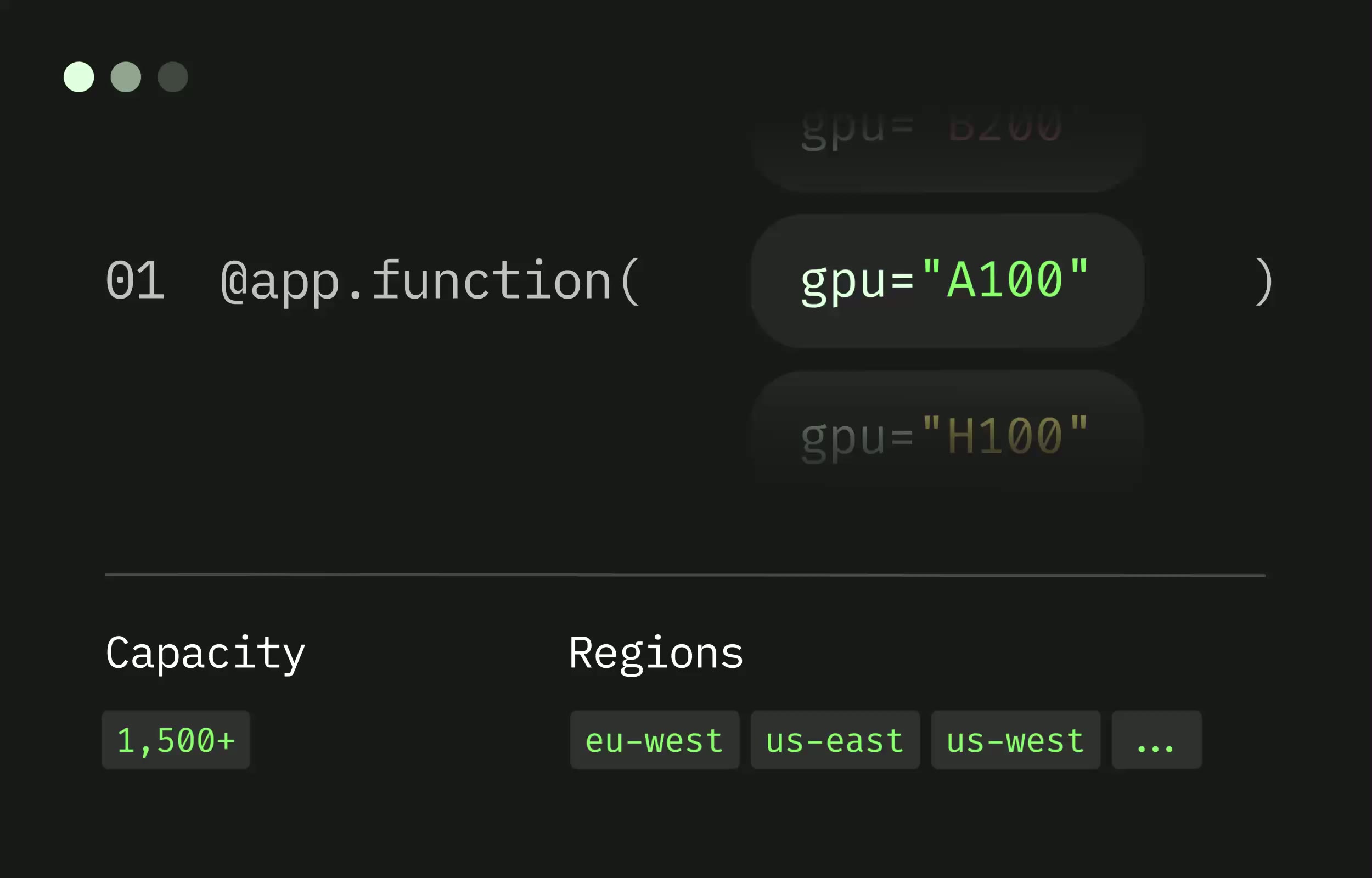
The honest complaints are real. The most-upvoted critique on the WaveSpeed and Blaxel comparison blogs is that Modal is great infrastructure but you still build the product yourself — there is no "one-click hosted Stable Diffusion" or managed fine-tuning service. Several threads also call out that regional multipliers (1.25x–2.5x) and the non-preemptible surcharge (up to 3x) stack to a combined 3.75x multiplier for a production US workload, which is rarely reflected in the marketing pricing page. GPU availability during peak H100 demand has been a second recurring pain point.
Modal uses a freemium model with per-second usage billed on top. Self-hosting is not an option — this is a managed cloud.
| Plan | Price | Key Limits |
|---|---|---|
| Starter | $0/month | $30/month compute credits, 3 workspace seats, 100 containers, 10 concurrent GPUs |
| Team | $250/month | $100 included compute credits, unlimited seats, 1,000 containers, 50 concurrent GPUs |
| Enterprise | Contact | Dedicated capacity, SOC-2 & HIPAA, private cloud, SAML SSO, custom MSA |
Indicative GPU rates, in US, preemptible: H100 ~$0.001097/sec (~$3.95/hr), A100 80GB ~$0.000694/sec (~$2.50/hr), A100 40GB ~$0.000583/sec (~$2.10/hr), L4 ~$0.000222/sec (~$0.80/hr), T4 ~$0.000164/sec (~$0.59/hr). Regional multipliers apply outside the base region, and non-preemptible commitments carry up to a 3x surcharge.
Best for: AI engineers, ML researchers and small-to-mid infra teams shipping inference, fine-tuning, batch ETL or agent workloads who want to keep a Python-first mental model and avoid owning a Kubernetes cluster. Especially strong for LiteLLM-style routers, Bolt-style code execution backends, and any workload that bursts from zero to hundreds of GPUs unpredictably.
Not ideal for: teams with steady 24/7 GPU utilization (a reserved A100 on Lambda Labs or CoreWeave will beat Modal on cost), workflows that are not Python, or companies whose compliance posture forbids routing training data through a third-party cloud — Modal does not offer a self-hosted control plane.
Pros:
modal-examples repo for real-world patterns.Cons:
RunPod Serverless is the most direct competitor and often cheaper on raw GPU hours, but its developer experience is rougher and cold starts for large models lag. Beam and Cerebrium target the same Python-serverless niche with slightly different trade-offs — Cerebrium in particular competes hard on price. For steady 24/7 GPU workloads, Lambda Labs and CoreWeave reserved instances are cheaper. Teams who want managed inference rather than infrastructure tend to pick Together AI, Fireworks, or OpenRouter for pure LLM serving.
For a Python-first AI team that values iteration speed more than the last dollar of GPU cost, yes — Modal is the clearest pick in the serverless GPU category today. The $30/month free credits let you build a real product before paying anything, and the SDK is genuinely good enough that most teams stop wishing for a Dockerfile. If you already operate Kubernetes at scale and run GPUs 24/7, Modal's premium over reserved hardware will not pay for itself. We land at 86/100: a few points docked for the opaque multiplier pricing and the lack of any self-host option, but otherwise the most complete serverless compute product shipping in 2026.
gpu="H100".ServiceNow and Accenture Launch Forward Deployed Engineering Program to Scale Agentic AI in the Enterprise (May 6, 2026)
At Knowledge 2026, ServiceNow and Accenture announced a joint forward deployed engineering program that drops co-located engineer pods into customer environments to ship agentic AI workflows natively on the ServiceNow AI Platform — with access to 300+ pre-built agent skills and the AI Control Tower as the governance backbone.
May 7, 2026
ReFiBuy Raises $13.6M Seed to Help Brands Get Recommended by AI Shopping Agents (May 5, 2026)
ReFiBuy, the Raleigh-based agentic commerce platform from ChannelAdvisor founder Scot Wingo, closed an oversubscribed $13.6M seed led by NewRoad Capital Partners on May 5, 2026 — betting that the next billion-dollar e-commerce moat is being chosen by ChatGPT, Claude and Perplexity.
May 7, 2026
OpenAI Replaces ChatGPT's Default Model With GPT-5.5 Instant — 52.5% Fewer Hallucinations, 30% Shorter Answers (May 5, 2026)
OpenAI on May 5 swapped GPT-5.3 Instant for the new GPT-5.5 Instant as ChatGPT's default model, claiming 52.5% fewer hallucinated claims on high-stakes prompts and 30% more concise answers. The model also rolls into the API as chat-latest and adds personalization from Gmail and past chats for Plus and Pro web users.
May 7, 2026
Is this product worth it?
Built With
Compare with other tools
Open Comparison Tool →

