
 AI Tools
AI ToolsAider
AI pair programming in your terminal—free, open-source, any LLM
Helicone is an open-source LLM observability platform and AI gateway from YC W23 that adds traces, cost tracking, caching and prompt management to any OpenAI-compatible app with a single base-URL change.
Helicone is an open-source LLM observability platform and AI gateway that adds traces, cost tracking, caching and prompt management to any OpenAI-compatible app with a single base-URL change. We rate it 82/100 — the fastest on-ramp in the category for teams that want production-grade LLM monitoring without giving up self-hosting or vendor neutrality, provided you can live with a UI that still trails Langfuse on depth and a free tier that is noticeably tighter than the open-source competition.
Helicone is built by Justin Torre and Cole Gottdank, co-founders who went through Y Combinator's W23 batch and first shipped the platform in . The company's pitch is to give developers "Datadog for LLMs" — a control plane that sits between your app and whatever model provider you use, logs every request, and surfaces cost, latency and quality metrics without requiring you to redesign your code.
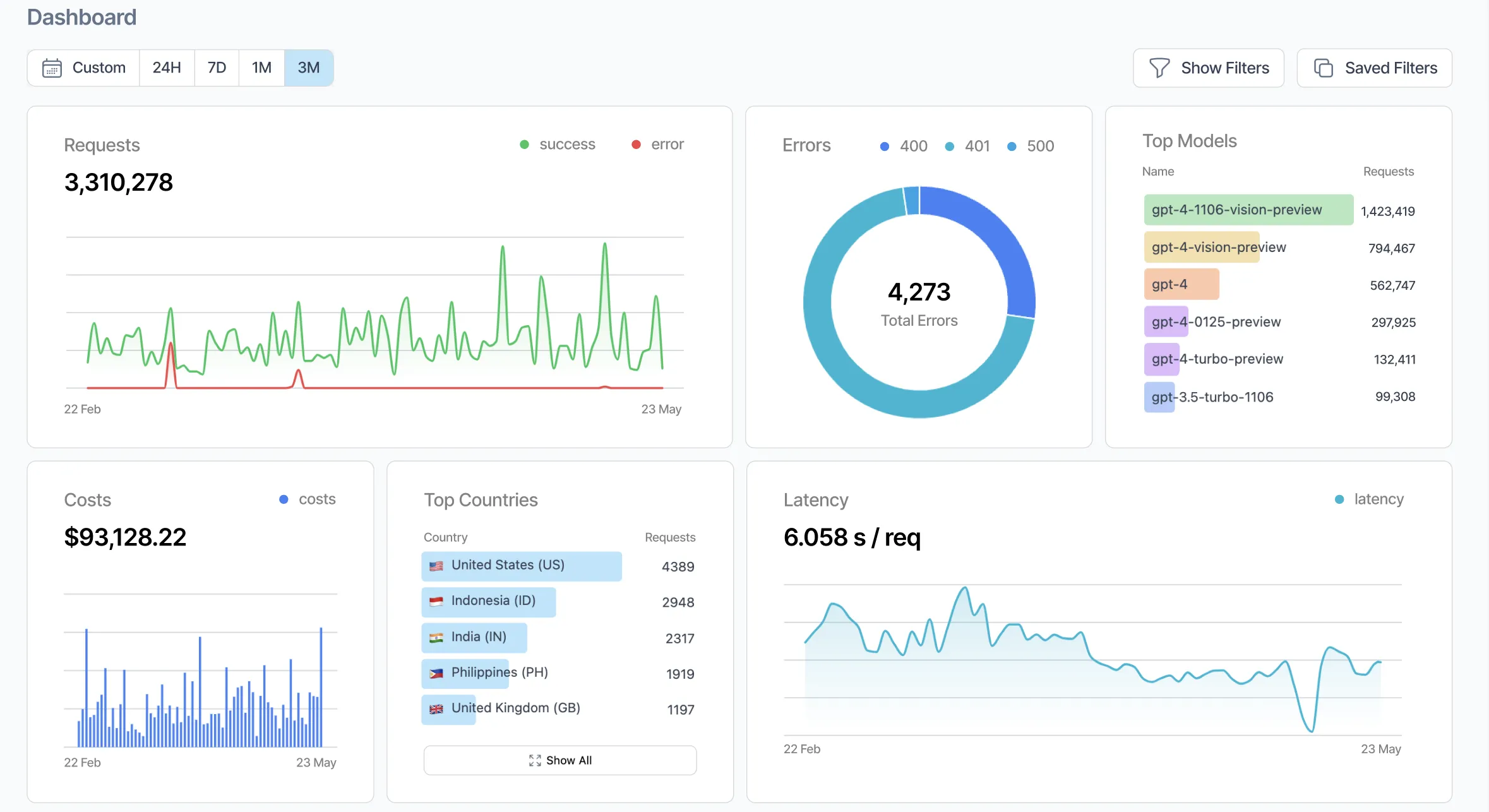
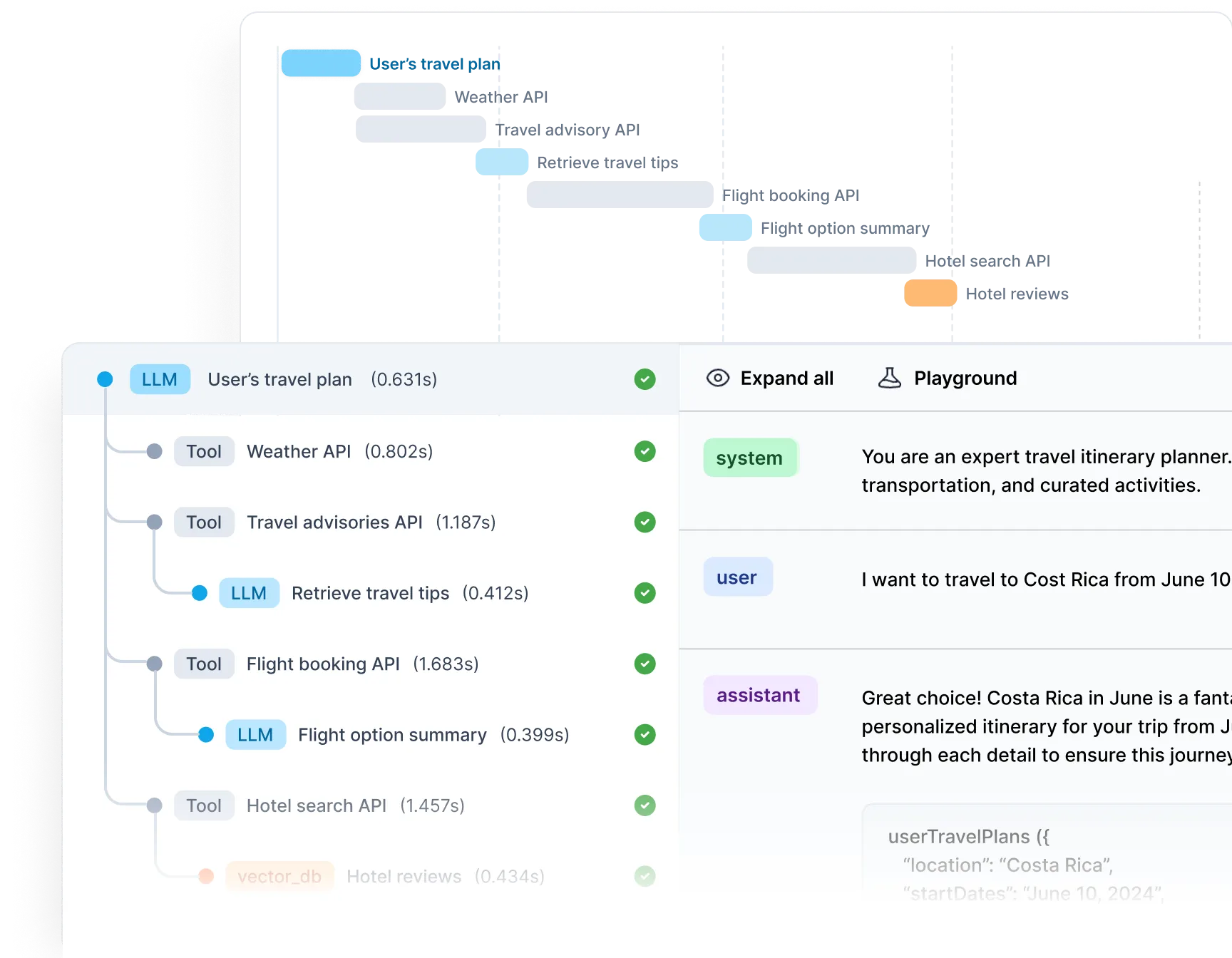
As of the open-source repo at github.com/Helicone/helicone has 5,500+ stars, ships under the Apache-2.0 license, and runs on TypeScript with Cloudflare Workers, ClickHouse and Kafka under the hood. The company says its gateway has now processed over 2 billion LLM interactions, and the v2025.08.21 release line added a proper development lifecycle — log, evaluate, experiment, review, release — that moved Helicone from "a nice logger" to something closer to LangSmith's scope.
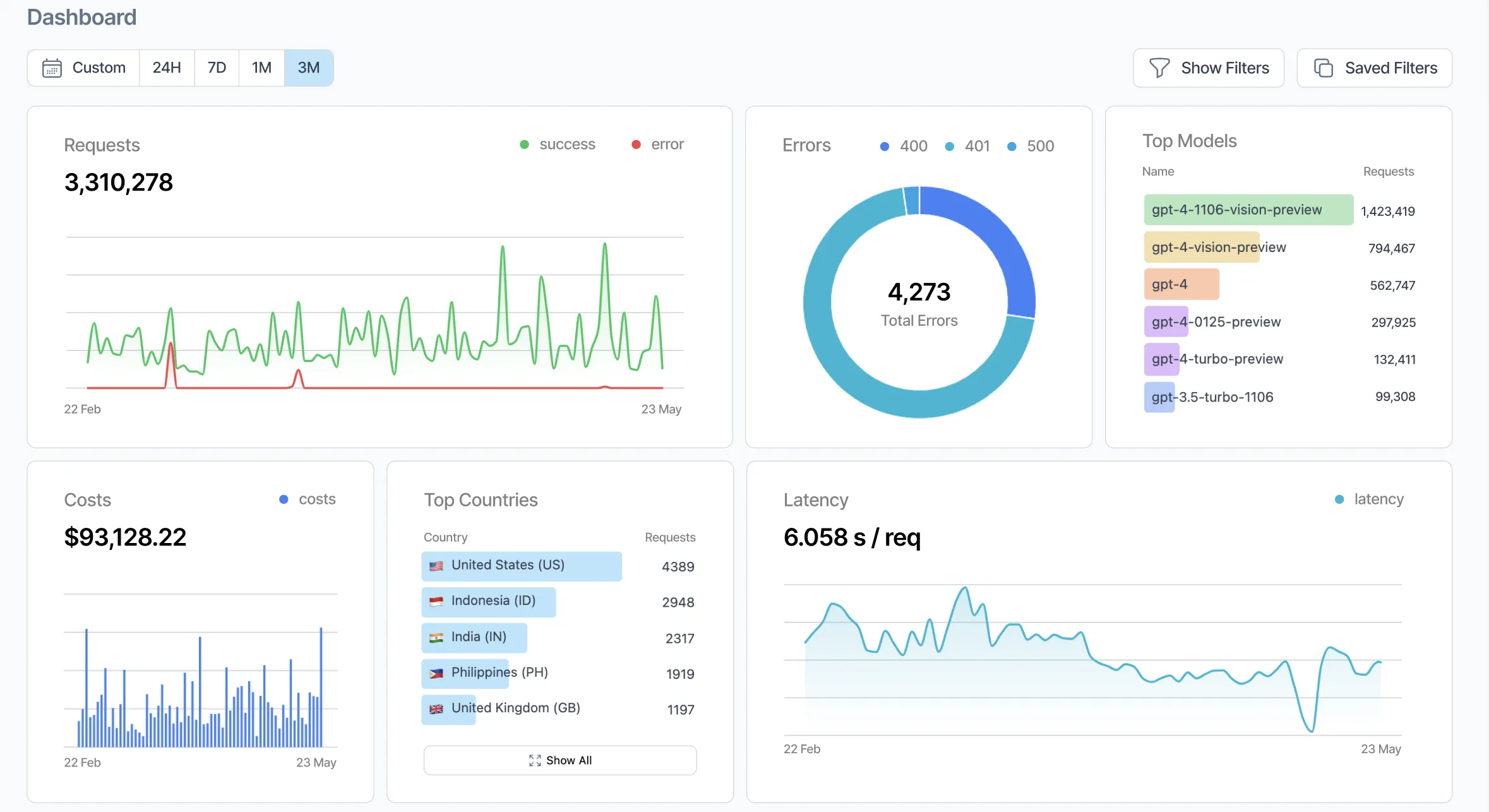
api.openai.com to oai.helicone.ai (or the equivalent Anthropic, Gemini or OpenRouter proxy) and you are logging. No SDK wrappers, no decorators, no code rewrites — Helicone's distributed proxy adds on average 50–80ms of latency.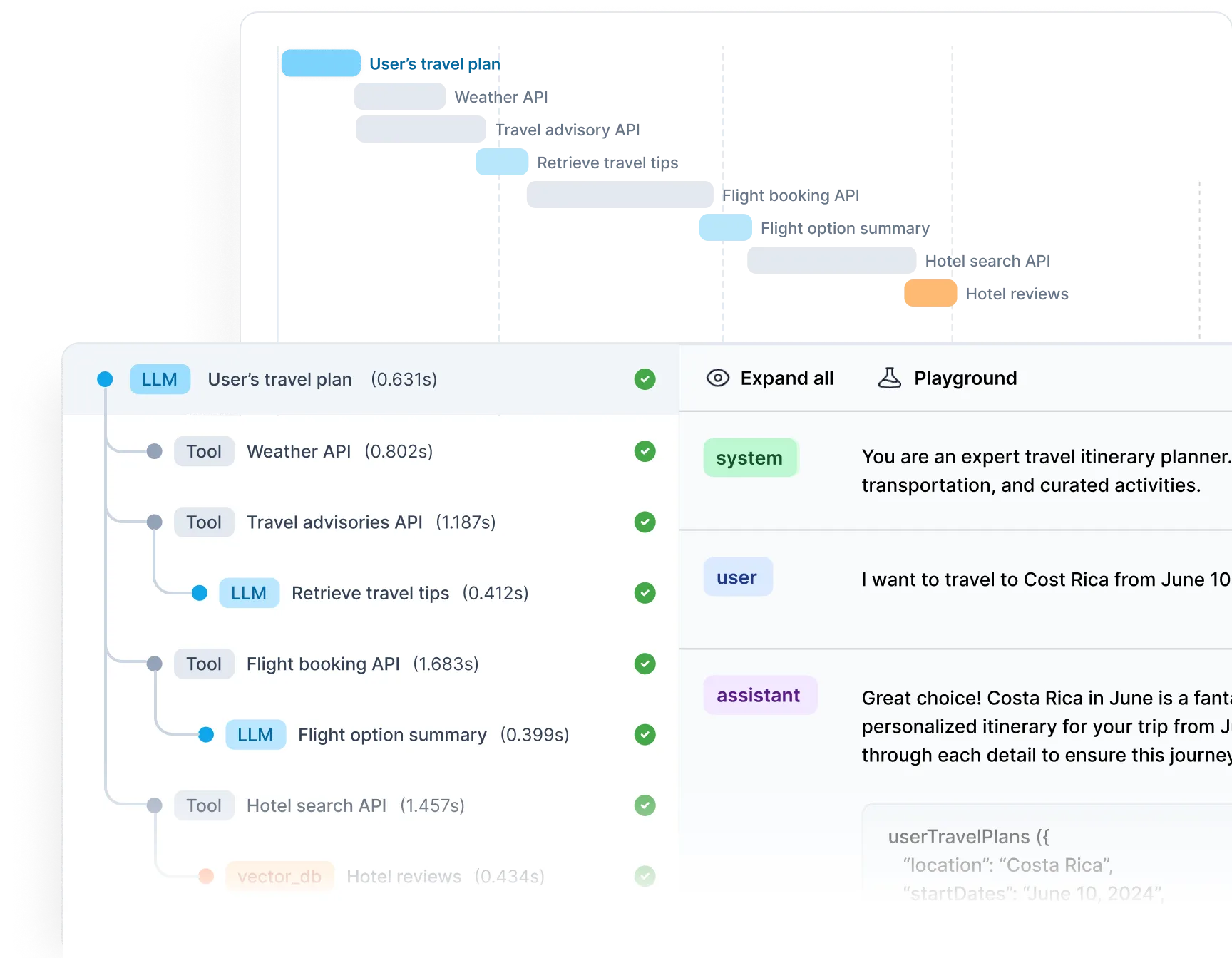
On Product Hunt, Helicone holds a 5.0 average across 13 reviews and cleared 166 upvotes at launch, with reviewers repeatedly calling out the "works out of the box" setup and the concrete savings from caching. On Hacker News, the v2 Show HN thread (42806254) drew mostly positive reactions from YC peers and independent builders, with the common refrain being that the one-line proxy is the thing that got them to try it instead of LangSmith.
Complaints are real. On Reddit's r/LocalLLaMA and r/LangChain, the recurring knock is that Helicone's evaluation and dataset tooling is still less mature than Langfuse or LangSmith — good enough for basic regressions, not yet good enough for serious eval suites. A few engineers also note that the 10k request/month free tier is generous for hobby projects but disappears fast in production, pushing teams onto the $79 Pro plan sooner than they expected.
Helicone uses a freemium model with usage-based overages above each tier's included allowance. Self-hosting the open-source build is always free.
| Plan | Price | Key Limits |
|---|---|---|
| Hobby | $0/month | 10k requests, 1GB storage, 7-day retention, 10 logs/min, 1 seat |
| Pro | $79/month | 10k free + usage-based, unlimited seats, alerts, HQL, 1-month retention |
| Team | $799/month | 5 orgs, SOC-2 & HIPAA, dedicated Slack, 3-month retention, 15k logs/min |
| Enterprise | Custom | SAML SSO, on-prem, forever retention, 30k logs/min, custom MSA |
Best for: solo builders and small engineering teams shipping LLM features who want proper observability, cost tracking and caching without a LangChain-style framework lock-in. Especially useful for teams already using OpenRouter or multi-provider setups where a single gateway is the point.
Not ideal for: companies that need the deepest eval tooling in the category (pick Langfuse or LangSmith), or teams whose compliance posture rules out proxying traffic through a third-party gateway at all — in which case the self-hosted Helm chart is the only viable option.
Pros:
Cons:
Langfuse is the other serious open-source option, with stronger evals and a simpler single-Postgres architecture, but no built-in caching. LangSmith is the most polished commercial product and the default if you are already deep in LangChain, but it is proprietary and has no caching layer. Braintrust is the heavyweight choice for eval-first teams, at a correspondingly higher price point.
Yes — for most teams shipping LLM features in 2026, Helicone is the right default. It gets you 80% of what LangSmith offers at roughly a third of the friction, ships the cost controls and caching LangSmith does not, and keeps a credible self-host story that Langfuse fans will also appreciate. We rate it 82/100: very good, with a couple of real rough edges around evals and free-tier limits that keep it out of the 90s for now.
ServiceNow and Accenture Launch Forward Deployed Engineering Program to Scale Agentic AI in the Enterprise (May 6, 2026)
At Knowledge 2026, ServiceNow and Accenture announced a joint forward deployed engineering program that drops co-located engineer pods into customer environments to ship agentic AI workflows natively on the ServiceNow AI Platform — with access to 300+ pre-built agent skills and the AI Control Tower as the governance backbone.
May 7, 2026
ReFiBuy Raises $13.6M Seed to Help Brands Get Recommended by AI Shopping Agents (May 5, 2026)
ReFiBuy, the Raleigh-based agentic commerce platform from ChannelAdvisor founder Scot Wingo, closed an oversubscribed $13.6M seed led by NewRoad Capital Partners on May 5, 2026 — betting that the next billion-dollar e-commerce moat is being chosen by ChatGPT, Claude and Perplexity.
May 7, 2026
OpenAI Replaces ChatGPT's Default Model With GPT-5.5 Instant — 52.5% Fewer Hallucinations, 30% Shorter Answers (May 5, 2026)
OpenAI on May 5 swapped GPT-5.3 Instant for the new GPT-5.5 Instant as ChatGPT's default model, claiming 52.5% fewer hallucinated claims on high-stakes prompts and 30% more concise answers. The model also rolls into the API as chat-latest and adds personalization from Gmail and past chats for Plus and Pro web users.
May 7, 2026
Is this product worth it?
Built With
Compare with other tools
Open Comparison Tool →